
楽天グループ株式会社(以下、楽天)は、本日、Mixture of Experts(MoE)アーキテクチャを基にした新しい日本語の大規模言語モデル(以下、本LLM)「Rakuten AI 2.0」と、初の小規模言語モデル(以下、本SLM)「Rakuten AI 2.0 mini」の2つのAIモデルを発表しました。これらのモデルは、2024年12月に発表されたもので、それぞれ基盤モデルとインストラクションチューニング済モデルを提供することにより、様々なビジネスシーンでの活用を目指しています。すべてのモデルはApache 2.0ライセンスで配布され、楽天の公式「Hugging Face」リポジトリから容易にダウンロード可能です。
人間の嗜好を反映させる革新な手法
「Rakuten AI 2.0」の基盤モデルは、最先端のSimPO(Simple Preference Optimization with a Reference-Free Reward)を用いたファインチューニングが行われ、人間に近い嗜好とのアライメント最適化を実施しました。従来の強化学習手法であるRLHF(Reinforcement Learning from Human Feedback)やDPO(Direct Preference Optimization)と比べて、SimPOはシンプルで安定しており、さらにコスト効率も高いため、実用的な代替案と言えます。
日本語における卓越した性能
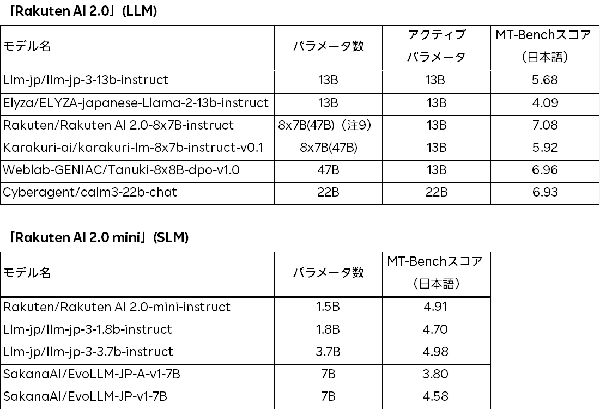
楽天は、会話形式や指示形式のデータを用いて基盤モデルをファインチューニングし、その後、インストラクションチューニング済モデルを日本語版MT-Benchで評価しました。この評価では、会話能力と指示に対する応答能力が特に重要視されています。「Rakuten AI 2.0」インストラクションチューニング済モデルは、同等のアクティブパラメータ数を持つモデルの中で、日本語版MT-Benchで最も高い性能を示しました。さらに、「Rakuten AI 2.0 mini」も同様のサイズのオープンモデル中で最高のパフォーマンスを達成しています。
これらのモデルは、コンテンツの要約、質問応答、一般的なテキスト理解、対話システムの構築など、幅広いテキスト生成タスクでの商業利用が可能です。加えて、新しいモデルを開発する際の基盤としても機能します。
楽天グループのChief AI & Data Officer(CAIDO)、ティン・ツァイ氏は、次のように述べています。「私たちの新しいAIモデルは、企業が迅速に価値を実現できるよう、効果的でコストパフォーマンスの良いソリューションを提供します。オープンモデルのリリースは、日本におけるAI開発を加速するものと考えています。日本全体の企業が、AIを活用して新サービスや製品を創り出し、成長する過程を支援するコミュニティを構築したい」とのことです。
新AIモデルの特徴
楽天は、AIアプリケーションを開発する企業や技術者のために、以下のモデルを提供しています。
・「Rakuten AI 2.0」: これは、2024年3月に公開された日本語に特化した高性能LLM「Rakuten AI 7B」を基に開発された8x7BのMoEモデルです。本LLMは、8つの70億パラメータで構成される「エキスパート」と呼ばれるサブモデルから成り、高品質な日本語と英語のデータセットを用いて継続的に学習を行っています。
・「Rakuten AI 2.0 mini」:これは15億パラメータを有するモデルで、内製された多段階データフィルタリングとアノテーションプロセスを通じて、高品質、かつ多様な日本語と英語のテキストデータで学習されています。
楽天は現在、LLMの研究と開発に取り組んでおり、顧客向けにより快適なサービスを提供するため、今後もさまざまな選択肢を検討・評価し続けます。また、社内モデル開発を通して、LLMに関する専門知識を高め、「楽天エコシステム」を支援するために最適化されたモデルを目指します。
さらに、「AI-nization」という言葉をテーマに掲げた楽天は、ビジネスの全ての側面でAIを活用する取り組みを進め、より豊かなデータと先端技術をもって世界中へ新たな価値を提供していきます。
(注1)Mixture of Expertsアーキテクチャは、モデルが複数のサブモデル(エキスパート)に分割され、その中から最適なエキスパートのサブセットのみを活性化させて推論や学習を行えるAIモデルの構造です。
(注2)基盤モデルとは、大量のデータをもとに事前学習され、特定のタスクに微調整可能なモデルを指します。
(注3)インストラクションチューニング済モデルは、指示データで改良された基盤モデルで、利用者の指示に応じて応答を生成できる能力があります。
出典元:楽天グループ株式会社 プレスリリース












