
楽天グループ株式会社(以下「楽天」)は本日、新たにMixture of Experts(MoE)(注1)アーキテクチャを利用した日本語の大規模言語モデル(以下「LLM」)「Rakuten AI 2.0」と、日本初の小規模言語モデル(以下「SLM」)「Rakuten AI 2.0 mini」を発表しました。これらの新しいAIモデルは、AIアプリケーションを開発する企業、技術者、専門家を支援することを目的としており、来春にはオープンソースコミュニティに向けて公開される予定です。
「Rakuten AI 2.0」は、2024年3月に発表された日本語に最適化された高性能LLMの基盤モデル「Rakuten AI 7B」を基にしており、8x7BのMoE基盤モデル(注2)として設計されています。このモデルは、8つの70億パラメータで構成されるサブモデル「エキスパート」で機能し、ルーターによって選ばれた最も適切な2つのエキスパートが処理を行います。いずれのエキスパートとルーターも、日本語と英語の高品質な言語データを用いて継続的に学習を重ねます。
また、楽天が初めて開発した小規模モデル「Rakuten AI 2.0 mini」は、15億パラメータの基盤モデルであり、内製の多段階データフィルタリングとアノテーションプロセスを経て作られた広範な日本語および英語データセットを基に学習します。これにより、テキスト生成において高いパフォーマンスと精度を実現しています。
楽天グループのChief AI & Data Officer(CAIDO)であるティン・ツァイ氏は、次のようにコメントしています。
「楽天では、AIを人々の創造性と効率性を高めるためのソリューションと捉えています。今年3月には、様々な課題解決のためにAI技術を活用した高性能な日本語LLM『Rakuten AI 7B』を発表しました。今回開発された日本語に特化したLLMと初のSLMは、高品質な日本語データ、革新的なアルゴリズム、エンジニアリングにより、通常を超える効率を実現しています。これは、日本の企業や専門家がAIアプリケーションをユーザーに提供する上で重要なマイルストーンとなるでしょう。」
■「Rakuten AI 2.0」の概要
「Rakuten AI 2.0」は、入力トークンに対して最も関連性の高いエキスパートを動的に選定する高度なMoEアーキテクチャを採用しており、計算効率とパフォーマンスの最適化を図っています。このLLMは、8倍の大規模モデルに匹敵するのにもかかわらず、計算資源の消費量は約1/4に抑えられています(注3)。
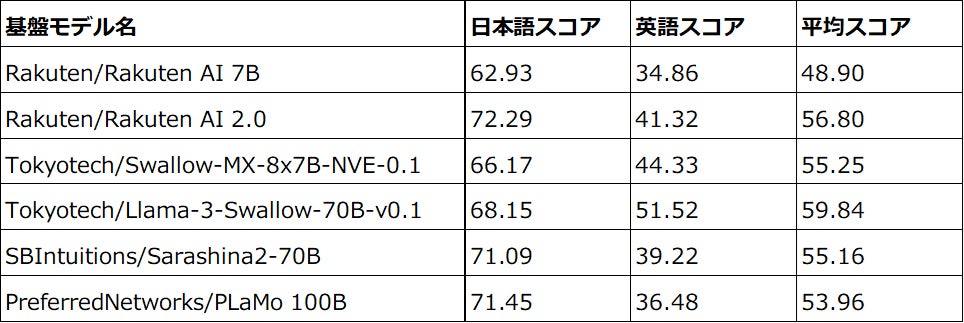
■パフォーマンス評価
楽天は、日本語および英語の能力を測定するためにLM-Harness(注4)を使用してモデル評価を行いました。リーダーボードは対象言語の特性を反映した広範な自然言語処理および理解タスクに基づいて評価され、「Rakuten AI 2.0」の日本語におけるパフォーマンスは「Rakuten AI 7B」と比較して8つのタスクで62.93から72.29に向上しました。
■「Rakuten AI 2.0 mini」の特徴
このSLMはコンパクトサイズで、モバイル端末への導入が可能であり、自社でのデータ運用も実現できます。大規模モデルと比較して、プライバシー保護、低遅延、コスト効率が求められる特定アプリケーションでの利用に適しています。
AIエンジニアリング統括部のジェネラルマネージャーであるリー・ション氏は、「新たなLLMを発表できることをとても嬉しく思っています。『Rakuten AI 2.0』はMoEアーキテクチャを用いることで、従来のモデル以上のコスト削減と高性能を実現しました。このLLMは多様性と効率性を提供でき、日本語モデルにおける新たな基準を確立するでしょう。また、『Rakuten AI 2.0 mini』はエッジでの運用を念頭に置いた優れたコンパクトモデルであり、革新をもたらすと信じています。」と述べています。
楽天は、最新のLLMおよびSLMをオープンなモデルとして推進することで、オープンソースコミュニティへの貢献と日本語LLMのさらなる向上を目指しています。また、最新のLLMモデル開発を続けることにより、知識と経験を積み重ね、「楽天エコシステム」の拡大に繋げでいく方針です。
さらに、楽天は「AI化」を意味する造語「AI-nization(エーアイナイゼーション)」をテーマに、さらなる成長に向けてビジネスのあらゆる面でAIの活用を推進しています。これにより、豊富なデータと最先端の技術を駆使して、世界中の人々に新たな価値を提供することを目指しています。
(注1)Mixture of Expertsアーキテクチャは、モデルを複数のサブモデルに分割し、最も適切なエキスパートのみをアクティブにして入力処理を行うことで、高度な推論を実現します。
(注2)基盤モデルは、膨大なデータで事前学習され、特定のタスクやアプリケーションに微調整可能です。
(注3)MoE LLMにおける計算は、アクティブエキスパートとエキスパートの比率によるものです。
(注4)LM Evaluation Harnessによる評価テストの結果です。
出典元: 楽天グループ株式会社プレスリリース












